Java集合源码阅读
先附上二哥网站上关于集合框架的结构图
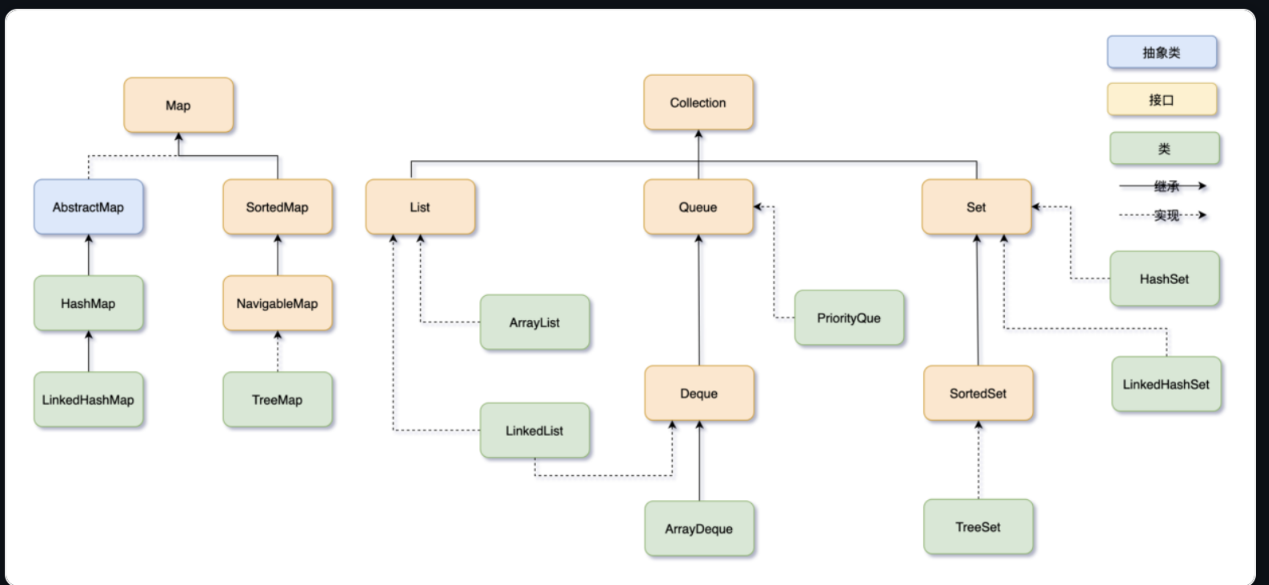
版本为JDK21
ArrayList 扩容机制
先介绍一下 ArrayList 中的关键变量:
-
transient Object[] elementData底层用来存储元素的数组 -
private int size;表示集合中元素的实际数量 -
private static final int DEFAULT_CAPACITY = 10;默认初始容量 -
private static final Object[] EMPTY_ELEMENTDATA = {};当用户调用new ArrayList(0)时,elementData 会引用该数组。 -
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};当用户调用默认构造参数时会引用该数组。
1 | private Object[] grow(int minCapacity) { |
上面是有关扩容的源代码。
添加元素(比如调用 add(E e) 方法)时会进行判断 if (s == elementData.length) elementData = grow() 如果当前元素数量(size)等于数组容量(elementData.length),则会触发扩容机制。
在无参 grow 方法计算 size + 1,也就是有参 grow 函数的参数 minCapacity(所需最小容量)。
当数组通过默认构造实现,且从未添加元素(即 oldCapacity == 0 && elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)时,会进入 else 分支,创建一个新数组,数组长度为10。
如果进入 if 分支,会计算新容量,newLength 方法如下
1 | public static int newLength(int oldLength, int minGrowth, int prefGrowth) { |
这段代码会比较 minGrowth 和 prefGrowth,一个表示最小增长量,一个表示首选增长量,在大多数情况下后者更大,所以一般情况下会说1.5倍扩容。计算得到 prefLength ,如果该值超过了最大容量限制,则调用 hugeLength 方法,这里不再描述。
得到 newCapacity 后,创建新数组并拷贝原数组数据,返回新数组,扩容结束。
有时创建集合时,可以在构造函数中指定数组大小,避免频繁的扩容。
HashMap 的 put 方法
1 | public V put(K key, V value) { |
第一步,在 put 方法里先将 key 传入 hash 函数(在该函数里,获得 key 的哈希值后进一步对其位运算和异或运算,扰乱哈希值,减少哈希冲突),然后将得到的值与其他值传入 putVal 函数。
1 | if ((tab = table) == null || (n = tab.length) == 0) |
第二步,如果数组为空,进行第一次数组扩容。同时计算索引位置,如果当前位置为空,则直接将键值对插入该位置。这里有个小技巧,当 n 是2的幂次方时 hash & (n - 1) 在效果上和 hash % n 是一样的。
1 | else { |
第三步,如果当前位置不为空,进入 else 分支。此时 p 指向当前桶位 tab[i] 的第一个节点。
全方位比较传入对象和变量 p 的属性:先比较哈希值,如果 hash 值不同,key 肯定不同。然后比较引用或值,一个判断内存地址是否相同,一个判断内容是否相同。如果条件都满足,证明找到了完全相同的 key ,将变量 e 指向 p。
如果进入 elseif 分支,会判断是否为红黑树节点,如果第一个节点不匹配,且该节点为 TreeNode 类型,说明该桶已树化,调用其他方法将新节点插入到红黑树中,在该方法中查找 key,找到则返回对应节点,找不到返回 null。
如果进入 else 分支,就是循环遍历链表,如果遍历到尾部也没找到,在尾部插入新节点,并判断是否需要树化。如果中途找到,则停止遍历。变量 e 指向找到的节点。
到这里 e 会有两种情况,如果 e != null,说明链表或红黑树中找到了已存在的 key,用新 value 覆盖旧 value,然后返回旧值。如果 e == null,说明没有找到,并成功在链表或红黑树中插入了新节点。
最后,根据 size 大小判断是否需要再次扩容。
整体思路是先查后改,查完之后变量 e 指向了需要更新的旧节点。
HashMap 传参初始化
先说结论,如果传的是 17,HashMap 会将容量调整到大于等于 17 的最小的 2 的幂次方,如果不传参默认值是 16。
1 | public HashMap(int initialCapacity) { |
相关代码如图,函数调用从上到下,最关键的是 tableSizeFor 方法。
第一步先将 cap 减一,这是为了处理 cap 本身就是 2 的幂次方的情况。
第二步进入 numberOfLeadingZeros 方法,该方法返回从最高位开始连续的 0 的个数,比如传入 15,返回 28(二进制表示共 32 位)。
第三步将 -1 无符号右移前导零的个数。-1 的二进制表示位 32 个 1(补码),无符号右移高位补 0。
第四步进行三元运算符判断。如果右移 32 位的话,先对 32 取模,比如 -1 右移 32 位还是 -1,因为 32 取模后为 0,相当于没有右移。
举个例子,当 cap 为 18 时,二进制表示为0000 0000 0000 0000 0000 0000 0001 0010,减一后为0000 0000 0000 0000 0000 0000 0001 0001,前导 0 有27个,所以将 -1 的二进制表示右移 27 个,得到0000 0000 0000 0000 0000 0000 0001 1111,十进制表示为 31,最后加 1 为 32。
1 | public static int numberOfLeadingZeros(int i) { |
接下来解释这段神奇的源码:把负数和 0 的情况排除后,先假设最高位在 31 位,如果 i >= 1 << 16,意思就是 i 大于等于 2 的 16 次方,说明最高位 1 一定在前 16 位中,这时 n 减 16,i 右移 16 位,这个操作相当于把 i 的低十六位丢弃,因为都是 0,然后将高 16 位移到低 16 位处理,如果 i 不大于等于 2 的 16 次方,就说明最高位 1 在后十六位,不做处理。接下来处理类似,在剩下的 16 位中,如果高 8 位满足条件,说明最高位 1 在这高 8 位中。n 减去 8,i 右移 8 位。
处理到最后, i 的值最多剩下 2 位,分别是 00 01 10 11,n - (i >>> 1) 实际上是在判断剩下 2 位中最高位 1 的位置。整体思想类似二分查找。
这个方法上有 @IntrinsicCandidate 注解,表明会使用专门的 CPU 指令来代替这段代码,从而获得极高的执行速度。
HashMap resize 扩容方法
常见的执行 resize 方法的有两种情况:第一次 put 时的初始化扩容;元素数量超过阈值时的扩容。
先贴一下完整的方法
1 | final Node<K,V>[] resize() { |
先说前面的条件判断:
第一种情况:正常扩容。此时 oldCap > 0,说明是因为元素过多触发了扩容。如果容量已达上限,将阈值设为 Integer.MAX_VALUE,这样就不会触发扩容了,直接返回旧数组;否则进入 elseif 分支(其实这个分支的条件我不理解),容量和阈值都翻倍。
第二种情况:带参构造初始化,此时 oldCap == 0 && oldThr > 0,初始容量设置为旧的 threshold。从上面的构造器源码可以看出,如果带参构造,loadFactor 和 threshold 将被赋值,所以 oldThr > 0。
第三种情况:无参构造,这种情况下指定容量为 16,阈值为 12(16 * 0.75)。
然后补充计算一下新阈值,因为如果是第二种情况,newThr 仍然为 0。
接下来是 resize 的后半部分。
首先更新属性 threshold,创建新数组并赋值给 table,接下来迭代遍历旧 table。注意 oldTab[j] = null,为了方便回收器回收。
第一种情况,该桶只有一个节点,根据公式计算新索引位置,公式在 put 方法里提到过
第二种情况,该位置是红黑树节点,调用 split 方法重新分配。
第三种情况,排除前两种后,该位置只可能是链表,使用特殊处理方法。
对链表的处理比较复杂,也是 jdk8 优化的地方,jdk7 会重新计算每个元素的哈希值,而现在可以通过位运算直接判断位置。核心就是根据条件构建两条链表,根据 e.hash & oldCap 的值,如果等于 0,将节点接入低位链(low),否则接入高位链(high)。链表遍历结束后将低位链放在原索引位置:newTab[j] = loHead; ,高位链移动到原索引 + oldCap 的位置上:newTab[j + oldCap] = hiHead。
推导一下涉及到的公式 (e.hash & oldCap) == 0:
明确元素在表中的位置由hash & (n-1)决定。那么 e.hash & oldCap 实际上是在检查哈希值中对应 oldCap 那个 1 的位是否为1:如果为 1,说明扩容后位置会移动 oldCap 的长度,也就对应了该公式:newTab[j + oldCap] = hiHead;如果为 0,说明扩容后位置不变。
举一个具体的例子,全部用二进制表示,所描述的第几位是从低位开始数。
假设 oldCap = 10000, newCap = 100000。
如果元素 e 的 hash 值为 000101,第五位为 0 ,说明扩容后索引位置不变,经过验证 e.hash & oldCap == e.hash & newCap。
如果元素 e 的 hash 值为 010101,第五位为 1 ,说明扩容后索引位置增加 oldCap,经过验证 (e.hash & oldCap) + oldCap == e.hash & newCap。
妙!