MySQL索引八股整理
整理一下MySQL索引的八股。
索引介绍
索引是数据库中用于加速查询的数据结构,通过对表中某列或多列的值进行排序,可以快速定位所要查找的数据。就像小时候在汉语字典里查字时,会先根据偏旁笔画数找到偏旁,然后根据剩余笔画找到目标字,这比在整个字典中一个一个查找是快很多的。
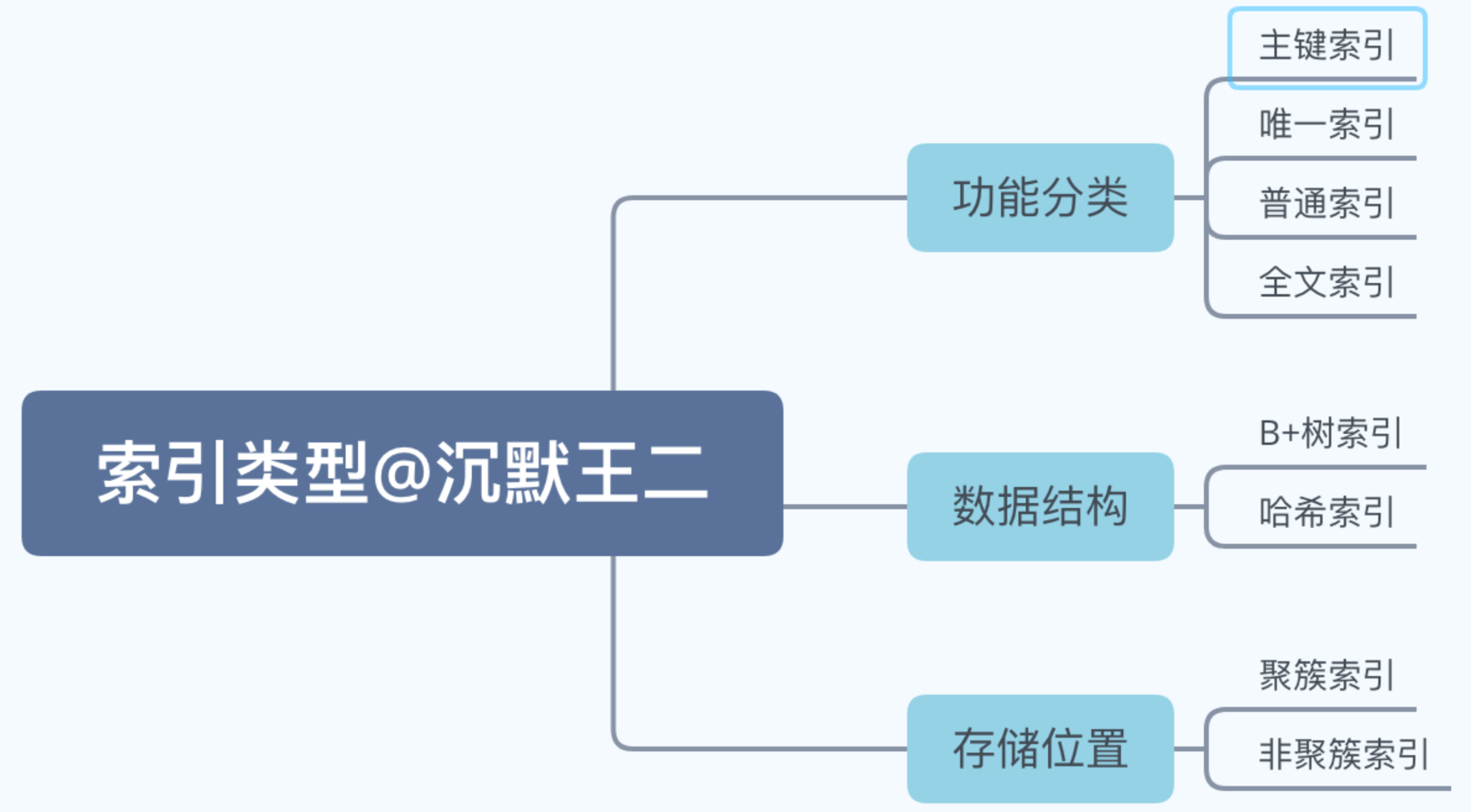
索引分类
索引有以下分类
索引详细介绍
主键索引:
主键索引用于唯一标识表中的每条记录,其值必须唯一且非空。每个表只允许有一个主键索引,一般为表中的自增id。
创建主键时,数据库会自动生成主键索引。若没有指定主键,MySQL的InnoDB存储引擎会优先选择一个非空的唯一索引作为主键,如果没有符合条件的索引,MySQL会自动生成一个隐藏的聚簇索引。
唯一索引:
主键索引 = 唯一索引 + 非空,每个表可以有多个唯一索引,同时唯一索引允许值为NULL,这是和主键索引不同的地方。唯一索引强制字段值的唯一性,插入或更新时会触发唯一检查,适用于业务唯一性约束的字段,比如邮箱。在建表定义唯一键时,会自动生成唯一索引。
键和索引的区别在于键时逻辑概念,而索引是物理实现,在磁盘中有着实际的存储。
普通索引:
普通索引仅用于加速查询,不会限制字段值的唯一性。
全文索引
全文索引是MySQL一种优化文本数据检索的特殊类型索引,适用于CHAR, VARCHAR, TEXT等字段。MySQL 5.7 及以上版本内置了 ngram 解析器,可处理中文、日文和韩文等分词。全文索引底层不再是 B+ 树索引。
建表时通过 FULLTEXT (title, body) 来定义。通过 MATCH(col1, col2) AGAINST('keyword') 进行检索,默认按照降序返回结果,支持布尔模式查询。
-
+表示必须包含; -
-表示排除; -
*表示通配符;
1 | -- 使用布尔模式查询 |
这样查询性能比LIKE '%keyword%'高很多。对于复杂的中文场景可以用Elasticsearch等专业搜索引擎替代。
B+ 树索引:
B+ 树是一种高度平衡的多路查找树,能有效降低磁盘的 IO 次数,并且支持有序遍历和范围查询。
相比普通二叉树,B+ 树可以将亿级数据量控制在3-4层树高,极大减少磁盘的 I/O 次数。因为树越高意味着查找数据时就需要更多的磁盘 IO,因为每一层都可能需要从磁盘加载新的节点。
相比二叉平衡树,B+ 树每个节点拥有多个子节点,可存储数据更多。
相比 B 树:B+ 树的非叶子节点只存储键值,叶子节点存储数据并通过链表连接,支持范围查询。这样的好处是非叶子节点不存储数据,就可以存储更多的键值对;叶子节点构成有序链表(双向链表),范围查询时可以直接通过叶子节点间的指针 顺序访问 整个查询范围内的记录,而无需对树进行多次遍历,查询效率高。

相比哈希表:B+ 树支持范围查询和排序
哈希索引:
Hash 索引基于哈希函数将键值映射到固定长度的哈希值,通过哈希值定位数据存储的位置,完全无序,只支持等值查找,速度快功能少,常见于 Memory 引擎。
InnoDB 内部使用了一种名为 “自适应哈希索引” 的技术,当某些索引值频繁访问时,InnoDB 会在 B+ 树基础上自动创建哈希索引,兼具两者的优点。
聚簇索引与非聚簇索引:
聚簇索引的叶子节点存储了完整的数据行,数据和索引是在一起的,不仅存储了主键值,还存储了其他列的值。
InnoDB 的主键索引就是聚簇索引,因此按照主键进行查询的速度会非常快。
每个表只能有一个聚簇索引,通常由主键定义。
非聚簇索引的叶子节点只包含了索引列和主键值,需要通过回表按照主键去聚簇索引查找其他列的值,唯一索引、普通索引等非主键索引都是非聚簇索引。回表通常需要访问额外的数据页,如果数据不在内存中还需要从磁盘读取,增加 I/O 开销。可通过覆盖索引或者联合索引来避免回表。
补充
一棵 B+ 树能存多少数据:
一棵 B+ 树能存多少数据,取决于它的分支因子和高度。在 InnoDB 中,页的默认大小为 16KB,当主键为 bigint 时,3 层 B+ 树通常可以存储约 2000 万条数据。
B+ 树相比 B 树的三个优势
-
B 树的每个节点既存储键值,又存储数据和指针,导致单节点存储的键值数量较少。
-
B 树的范围查询需要通过中序遍历逐层回溯;而 B+ 树的叶子节点通过双向链表顺序连接,范围查询只需定位起始点后顺序遍历链表即可,没有回溯开销。
-
B 树的数据可能存储在任意节点,假如目标数据恰好位于根节点或上层节点,查询仅需 1-2 次 I/O;但如果数据位于底层节点,则需多次 I/O,导致查询时间波动较大。
而 B+ 树的所有数据都存储在叶子节点,查询路径的长度是固定的,时间稳定为
O(logN)(N是数据总量),对 MySQL 在高并发场景下的稳定性至关重要。
联合索引介绍:
前面提到可通过覆盖索引或者联合索引来避免回表。如果一个查询只需要访问索引中已经包含的列,那么这个查询就可以被索引“覆盖”,不需要回表,这就是覆盖索引。至于联合索引就是把多个字段放在一个索引里,必须遵循 “最左前缀” 原则。
联合索引属于非聚簇索引。与单列索引不同的是,联合索引的每个节点会存储所有索引列的值,而不仅仅是第一列的值。
关于最左前缀涉及到的一些问题:
-
范围查询只能应用于最左前缀的最后一列。范围查询之后的列无法使用索引。
1
2
3
4SQL
-- 索引(a,b,c)
SELECT * FROM table WHERE a = 1 AND b > 2 AND c = 3;
-- 只能使用a和b,c无法使用索引 -
联合索引在 B+ 树中是按照最左字段优先排序构建的,如果跳过最左字段,MySQL 无法判断查找范围从哪里开始,自然也就无法使用索引。
-
如果查询模式是后缀通配符
LIKE 'prefix%',且该字段有索引,优化器通常会使用索引。否则即便是遵循最左前缀匹配,LIKE 字段也无法命中索引。 -
如果排序(order by)或分组(group by)的列是最左前缀的一部分,索引还可以加速操作。
索引下推:
索引下推是指:MySQL 把 WHERE 条件尽可能“下推”到索引扫描阶段,在存储引擎层提前过滤掉不符合条件的记录。
在传统的查询处理方式中,存储引擎首先根据索引读取数据并将其加载到内存中,然后在内存中应用 WHERE 子句中的过滤条件,筛选出符合条件的数据行。这种方式可能导致大量的数据传输,尤其是当数据量较大时。
而使用索引下推优化后,存储引擎在存储层就应用 WHERE 子句中的过滤条件,只有符合条件的数据才会被加载到内存中进一步处理。这可以减少数据传输量,从而提高查询效率。
其他问题
哪些情况下索引会失效:
-
对索引列使用函数或表达式会导致索引失效。
-
LIKE 模糊查询以通配符开头会导致索引失效。
-
联合索引违反了最左前缀原则,索引会失效。
-
使用 OR 连接非索引列条件,会导致索引失效。
-
使用
!=或<>不等值查询会导致索引失效。 -
(隐式类型转换也会导致索引失效)
创建索引有哪些注意点:
-
选择合适的字段。比如说频繁出现在 WHERE、JOIN、ORDER BY、GROUP BY 中的字段。优先选择区分度高的字段,比如用户 ID、手机号等唯一值多的,而不是性别、状态等区分度极低的字段,如果真的需要,可以考虑联合索引。
-
要控制索引的数量,避免过度索引,每个索引都要占用存储空间,单表的索引数量不建议超过 5 个。
-
联合索引的时候要遵循最左前缀原则。区分度高的字段放在左侧,等值查询的字段优先于范围查询的字段。例如
WHERE A=1 AND B>10 AND C=2,优先(A, C, B)。
全篇整理自二哥博客。